Dit artikel is alleen in het Engels beschikbaar.
Automatic image classification in Cleo
Written by Thomas Derksen (developer at Goldmund, Wyldebeast & Wunderliebe) on behalf of Aincient. Cleo is an initiative of Aincient.
Cleo is a platform containing Egyptian objects from four major international museum collections. These collections are standardized by using the Thot thesauri, and are automatically translated into English and Dutch. In addition to a traditional text-based search and filter of the collections, Cleo uses Artificial Intelligence (AI) to facilitate image search. It uses a trained neural network for multi-class image classification to classify user-uploaded images, using predetermined object classes (see figure 1). It is also possible to select one or multiple objects from the database, and to find similar objects based on this selection. In that case, object metadata is used to get the most relevant results. These features allow people to find other Egyptian objects based on objects they are interested in, or to find out more about Egyptian objects they come across in real life.
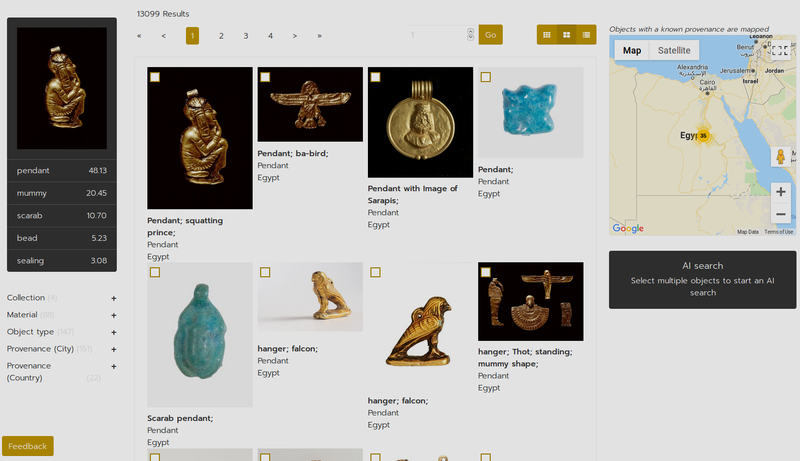
Figure 1: Classifying a user-uploaded image.
Uploading new images
One of the main features of Cleo is its capability to find similar objects based on user-uploaded images. If, for example, somebody comes across an interesting object in a museum or on the internet, it is possible to upload an image of that object to Cleo to find similar items and to get to know more about the object. Because we cannot control the quality, lighting, or orientation of the uploaded images, the underlying algorithm has to be very robust and adaptable.
There are currently 23 possible object classes, including ‘scarab’, ‘coin’, or ‘canopic jar’ (see figure 2 for a full list of all object classes). For each of these classes, Cleo calculates the probability that the uploaded image depicts an item from that class. It searches the database for objects with similar class probabilities, and presents items that belong to one of the three most probable classes at the top of the search results. The search results are ordered by their relevance, and the five highest class probabilities are displayed (see figure 1).
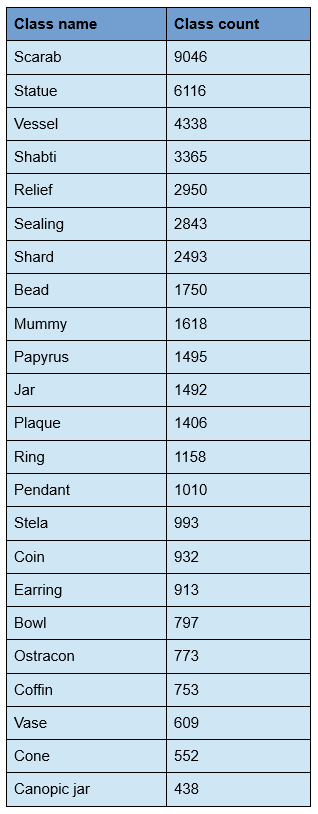
Figure 2: Object classes.
Finding similar objects
It is possible to select one or more items from the collections and search for similar collection items. Class probabilities are calculated for the images of each item, and all of these probabilities are averaged to get an overall class prediction. Items that are made from the same material, are from the same time period, or are from the same object class as the queried items get a small relevance boost. The 30 most relevant items are returned in order of their relevance. It is possible to select multiple search items from a results page, or to select just one item from its detail page. An example of this functionality can be found in figure 3 and in figure 4.
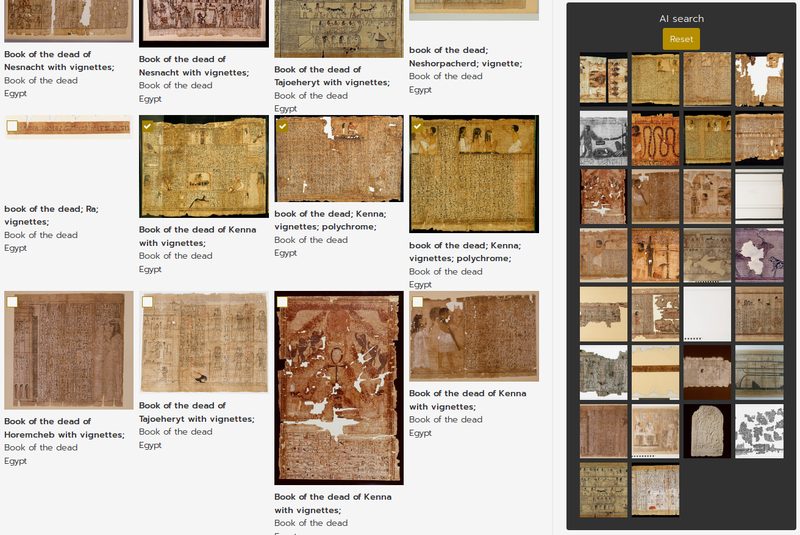
Figure 3: Finding similar items from multiple search results.
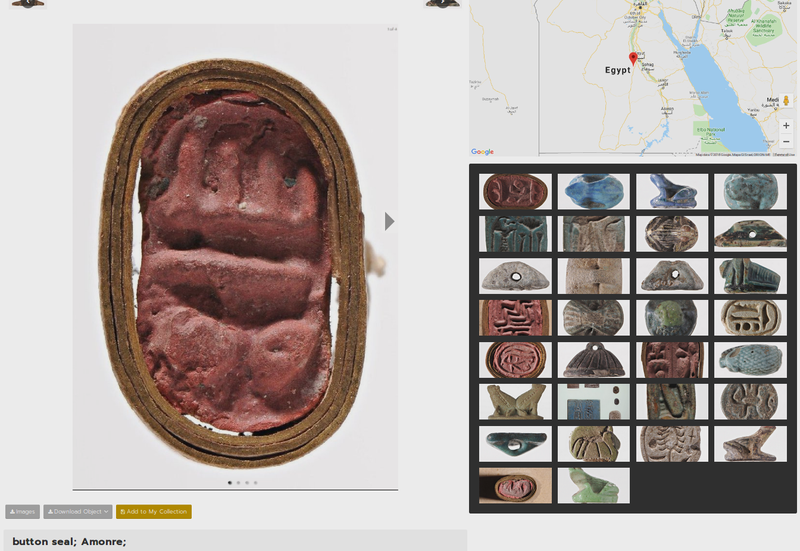
Figure 4: Finding similar items from an item detail page.
The algorithm
Images are classified using a convolutional neural network. The network loads a pre-trained convolutional base (the VGG-19 model) and, additionally, uses fine-tuning and transfer learning to train its own classifier. 33279 labeled training images are used to optimize the network.
The Cleo network is trained on top of the convolutional base of the VGG-19 model, a model of the 19-layer network used in the ILSVRC-2014 competition. The VGG-19 model has been trained on the ImageNet data set, a data set of over 14 million images in more than 20 thousand categories. It is optimized to recognize high-level visual features. It would have also been possible to use other pre-trained image classification networks (such as Xception or ResNet), but we chose VGG-19 because of its high accuracy and relatively small number of layers, which increased computing time and prevented overfitting. We experimented with some other models, but they either slowed the process down way too much, or the results were significantly worse.
To train the Cleo network, the top of the VGG-19 model is replaced by two densely connected network layers. The final layer has a number of units equal to the number of our predefined object classes. Each unit corresponds to one of these classes, and outputs the probability that an image belongs to that class. The VGG-19 layers are frozen to ensure that their weights are kept intact. After training the top of the model for a sufficient number of epochs, the four top layers of the VGG-19 network are unfrozen, so they can be fine-tuned with our training data. The network is trained for a few more steps, and the results are analyzed to see if they are satisfactory. A summary of the network can be found in figure 5.
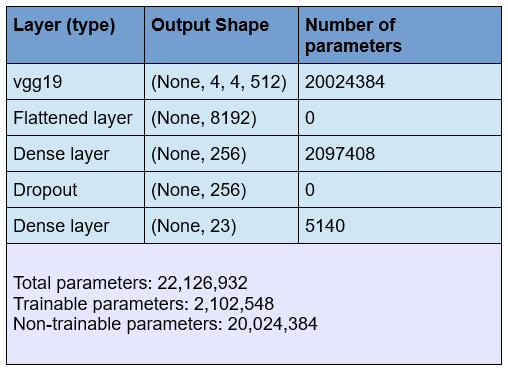
Figure 5: Summary of the neural network.
To get the most optimal results, as well as to prevent overfitting, the learning rate and number of training epochs are varied over multiple training runs. Once the network has been trained, the resulting model is saved and added to Cleo. All the images in the database are classified by the network, to get class probabilities that can later be compared to other objects or images.
The model can be used to classify user-uploaded images. It calculates the class probabilities for an image and compares it to the class probabilities of the items in our database. There are two search criteria: database items should either belong to one of the three most probable classes, or their class probability distribution (as calculated by the classification model) should be similar to that of the uploaded image. Objects are ranked based on the similarity of their probability distribution to the probabilities of the uploaded image.
The five most probable classes for the image are displayed, along with their probability scores.If the user selects one or more objects from the Cleo database, the network calculates the average probability scores for all of the images of these objects, by taking the mean of their probability distributions. The average scores are compared to the probability scores of other items from the database to retrieve similar items, in the same way as it is done for an uploaded image.
Objects in the database usually have associated metadata, which we can use to optimize the search results. Objects with a material, object type, or period that corresponds to the metadata of the queried items get a relevance boost. The 30 most relevant objects are shown in order of their relevance score. The impact of those boosts is visualized with an example in figure 6. It shows the results for a similar item search with and without the boosts. As you can see, the quality of the results changes significantly. While this is not necessarily true for all search queries (this is just an example), it shows that the boosts can have a big positive impact on the quality of the search results.

Figure 6: A similar item search with and without boosts
The training data
To train the network, we use about 33279 labeled training images from our database. The images are resized to 128*128 pixels, to reduce the file size of our training set and to decrease training time. Images keep their original aspect ratio, to preserve their original shape. They are automatically labeled based on the presence of certain keywords in the metadata. We only use classes with enough training examples, because using classes that are too small results in significant data imbalance and overfitting. The number of classes might be extended when more collections are added to the Cleo database. Currently, we are able to label 59% of the items in our database. The other 41% consists of items that are in a class that we cannot yet classify, and items that can’t be labeled properly based on their available metadata.
Because we have a very small number of training items for our number of classes, we apply a number of random transformations to the images, so the model never sees the exact same image twice. This process, known as data augmentation, helps prevent overfitting and improves generalization.
Another problem we have to deal with is class imbalance. Even though we exclude classes with a very small number of examples, some object classes still have a lot more examples than others. The smallest class contains 438 images, while the largest class has 9046. There are a few ways in which we try to combat this problem. First of all, we oversample very small classes (with fewer than 1000 images), by adding duplicate images to our data set. The risk of oversampling that comes with doing this is mitigated by our use of data augmentation.
Furthermore, we undersample our largest classes. Each class can contain a maximum of 2500 examples. Lastly, we also use the prior class probabilities to define class weights. This means that the influence an item has on the training process is inversely proportional to the number of examples of its class in the training set.
A randomly selected 1/6th of the data set is used for validation. The validation accuracy is monitored to make sure the network does not over- or underfit; it also helps to keep track of the performance of the network.
Implementation
Our image classification algorithm was implemented in Python using Keras, a package for machine learning in Python, with the TensorFlow backend. For training and optimizing the model, we used TensorFlow-gpu, which sped up the process by running everything on the GPU instead of the CPU.
We used the pre-trained VGG-19 model as the base of our network, and replaced the top with our own classifier. Our custom top consisted of a flattened layer, followed by a dense layer with 256 units, a dropout layer with a dropout rate of 0.4, and a final dense layer with 23 output units. A summary of the network can be found in figure 5.
We created training and validation sets by labeling 33279 images, resizing them to 128*128 pixels, and using a data format similar to the cifar10 format. We undersampled some of our largest classes by allowing a maximum of 2500 images per class, and oversampled our smaller sets by adding duplicates of existing images.
For training, we used the RMSprop optimizer with categorical cross entropy as the loss function. A custom generator was written to feed the network batches of 32 input tensors.With data augmentation, we apply a number of random transformations to the images to prevent overfitting. We calculate class weights based on the prior class probabilities using the sklearn ‘compute_class_weights’ function. Class weights are proportional to the prior class probabilities.
The first step of the training process was to freeze all the layers of the VGG19 model, and to train only the top. This is known as transfer learning. We trained the model for a minimum of 30 epochs, with a learning rate of 1e-4 and a learning rate decay of 1e-6. Then, we unfroze the last four layers of the VGG19 model and trained an additional 20 epochs with a learning rate of 5e-5 with no decay. This is known as fine-tuning the model. We tried out different learning rates and a different number of epochs, but these settings gave us the best results. A larger number of training epochs resulted in significant overfitting.
Design choices
The initial choice that had to be made was which technique to use to find similar items. Because we had no control over the quality, lighting, or orientation of the uploaded images, and because even within a class, objects can have large visual differences, simple image similarity techniques based on visual features (e.g. using edge detection) were not an option. That is why we decided to use automatic image classification based on neural networks. Because this task is highly specialized (the algorithm should be able to recognize all sorts of Egyptian objects, some of which look very much alike), there were no pre-trained image recognition algorithms that were suitable.
A point of discussion during the initial design was if we just wanted the algorithm to find similar images, or if we wanted to actually classify these images. It was decided to use image classification, mainly because this adds a lot of semantic information. When users upload an image, they probably want to know more about the object in the image. While image similarity allows us to return a list of similar items, it does not give explicit information about what the item in the uploaded image actually is. This information needs to be pieced together by looking at the search results and finding the similarities between these items. With image classification, it is still possible to retrieve similar items, but you also get a prediction of what is actually in the image. It also means that search results have more in common with the uploaded image than their visual appearance alone. Another reason to use image classification is because it would probably give better results with our relatively small training data set. While the performance of an image-similarity algorithm might improve significantly with larger data sets, it made more sense to use image classification at this stage of the project.
Currently, one way in which we calculate image similarity is by comparing the class probabilities of images and items. An item that has, for example, ‘scarab’, ‘vase’, and ‘bead’ as its three most probable classes is more similar to an item that has those same three classes at the top of its probability list than to an item that has ‘papyrus’, ‘mummy’, and ‘bead’ as its most probable classes. Using this as a sort of similarity metric is a somewhat heuristic approach, because the class probabilities do not directly correspond to the content of the images. However, because these probability scores are a high level abstract representation of the original image, similar probability distributions should indicate which images are also somewhat similar.
Our training data was automatically labeled based on textual information in the object metadata. It probably would have been more accurate to label the images by hand. Unfortunately, this was not a possibility. While 33279 images across 23 classes might not be very much for the task we were trying to accomplish, it would take way too much time to tag all the images manually, especially given the time frame of this project. The automatic labeling process was optimized as much as possible, but the results were still a bit noisy.
It should also be noted that we use two slightly different techniques for finding similar objects. For the image search, we only look at the class probabilities of the image and return images with similar probability distributions. For a search with items from our database, we also use metadata to boost some results. This last technique gives way better results, but, unfortunately, it is not a possibility for the image search. If a user uploads an image, we currently have no extra information about this image, so we can only use the visual information available.
Results
The performance of the current implementation of the algorithm is a good start, that needs further development. The search based on database items works decently well, but the image search often returns nonsensical results (an example can be found in figure 7). The validation accuracy of our network seems to top off at about 62%, and the accuracy between the different classes seems to vary significantly. The main reason for this is probably the small number of training examples for some of the classes and the noise introduced in our automatic labeling process. Our smallest class only has 438 examples, which is a very small number for such a highly specialized task. On top of that, not all items are labeled correctly, which results in even more unreliable data. The result of all of this is that the network starts to overfit after about 10 epochs, and even the training accuracy never seems to top 70%. Data augmentation, using class weights and under- and oversampling helps quite a lot, but is not enough to solve this problem completely.
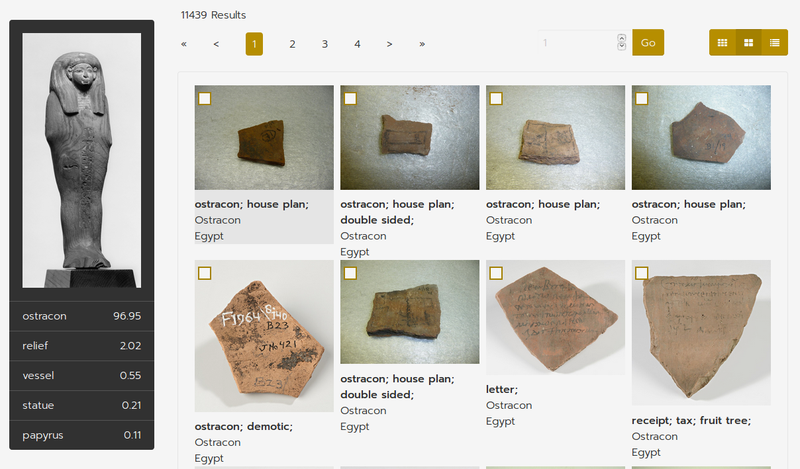
Figure 7: An example of a nonsensical classification result.
The overall and per-class precision, recall, and F1-score are displayed in figure 8. The F1-score is a weighted average of the precision and recall, with values ranging from 0 (worst) to 1 (best). The overall F1-score is only 0.24, which is already a problem, but it also varies significantly between the different classes. While the best scoring class (‘ushabti’) has an F1-score of 0.7, the worst scoring class (‘coffin’) has a score of 0.0, meaning that none of the 121 examples in our test set were recognized properly.
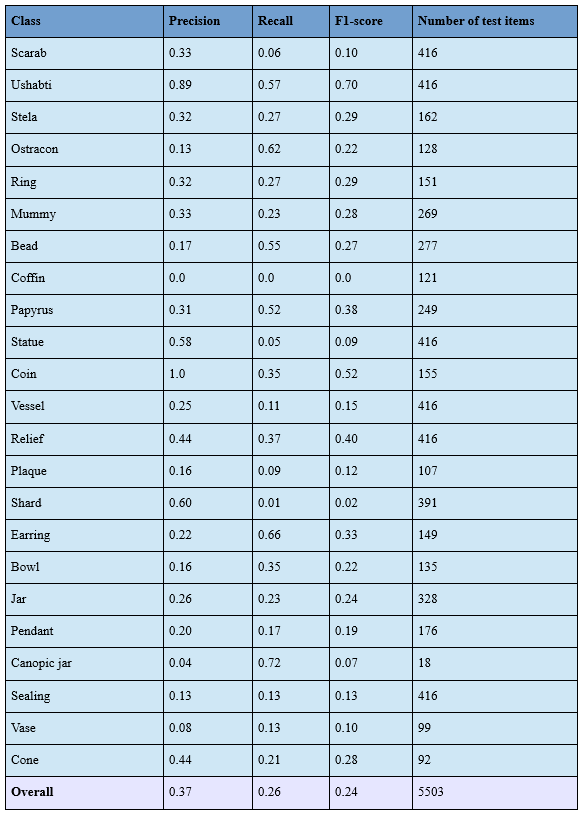
Figure 8: Results of the image classification.
Future work
A possible solution to improve the performance of the system is, as is often the case, getting more data. The inclusion of more collections in the Cleo database would increase the number of training images we have at our disposal, and should improve the accuracy of the network. This might also allow us to add additional object classes to our classifier, which means we can recognize more types of items.
Another improvement to the algorithm would be to predict more than just the object class. For example, it would also be possible to predict the material of the object in an image, or the period it comes from. Because the information we have about the material and period of items in our database is more reliable than the information about the item class, we could reliably label our items. Using the predictions about material or other meta-information, we could boost search results of objects with similar properties to the queried image.
Currently, we compare the output of the final layer of the network to determine the similarity between two images or objects. If the probability distributions are similar, we decide that the images or objects are probably similar as well. The information we get from this last network layer is not very rich, so it is possible that we can get better results when we compare the outputs of the penultimate layer instead.
In the similar item search, we currently use the material, period, and object type of items to boost relevant search results. This improved the quality of those results greatly. The results might even be better if we factor in more properties of the items. For example, most of the objects in our database have known size dimensions, which can be used to filter out search results of the wrong size.
One final extension to the system could be the feature to add multiple content labels to images automatically. If Cleo has the ability to recognize objects and text within an image, the semantic information it can generate becomes much richer and the classification can be much more precise. It would be possible to match, say, scarabs with a scorpion print on them to scarabs with the same print, or even other objects with scorpions on it. However, we would run into the same problems we have with the current implementation of the image classification. We would need a lot of precisely labeled data. A possible solution might be to use data from outside our database. We could even use the ImageNet classes and a pre-trained network.
All in all, the current implementation of our algorithm is a promising start. Hopefully, the performance of the algorithm will improve further when we add more collections to our database.